
这篇笔记内容主要来自Haproxy官方团队分享的一个幻灯片:《Haproxy best practice》,介绍了一些常规的配置方式和优化手段。
不要盲目使用文中出现的所有技巧。
Haproxy 是如何工作的
关于Haproxy 团队介绍,以及一些特性介绍直接看前面几张幻灯片即可。
Haproxy 的主要用作代理请求,工作流程如下:
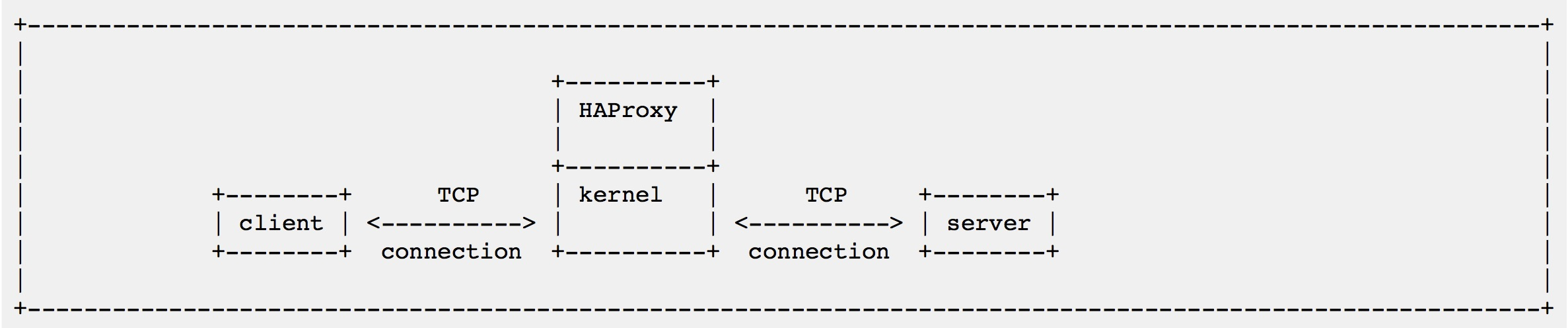
client 和Haproxy 建立连接,Haproxy 再和对应的后端server 建立连接,然后作为中间人,转发请求。 在Haproxy 配置中,对一个代理,会划分为2层,frontend(前端) 和backend(后端),这和上文说的Haproxy 的工作流程也是对应的。
配置例(来自幻灯片):
global
daemon
defaults
mode http
timeout client 10s
timeout connect 4s
timeout server 30s
frontend fe
bind 10.0.0.1:80
bind 10.0.0.1:443 ssl crt ./my.pem
default_backend be
backend be
server s1 10.0.0.101:80 check
server s2 10.0.0.102:80 check
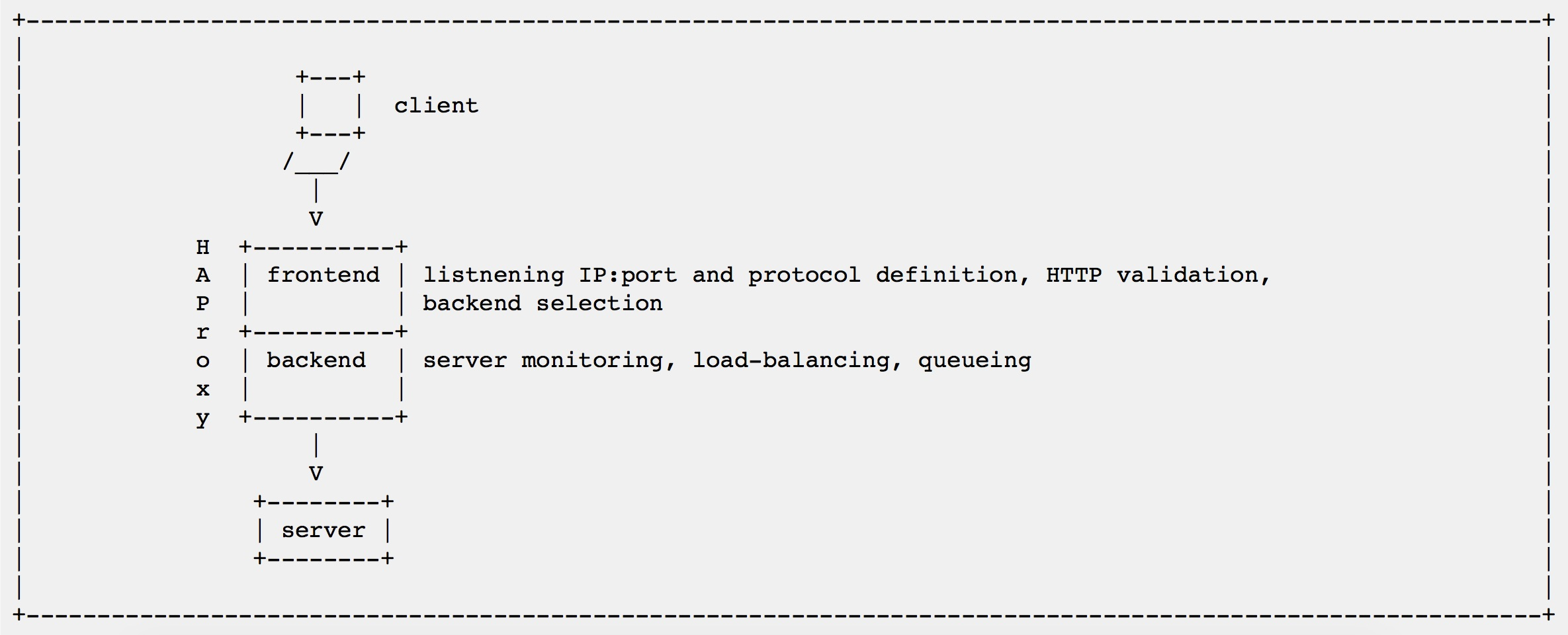
frontend:监听端口、协议代理定义,HTTP认证,后端选择等;
backend:监控server,负载均衡,队列。
可以看出,在frontend 中定义了要绑定的地址和端口,以及证书等,在backend,罗列了后端的IP和端口。不过要把2者合在一起写,也是可以的,使用listen 即可,如下:
listen http-in
bind *:80
server server1 127.0.0.1:8000 maxconn 32
A "frontend" section describes a set of listening sockets accepting client
connections.
A "backend" section describes a set of servers to which the proxy will connect
to forward incoming connections.
A "listen" section defines a complete proxy with its frontend and backend
parts combined in one section. It is generally useful for TCP-only traffic.
摘自 http://www.haproxy.org/download/1.4/doc/configuration.txt
RTF(W|E|L)M
阅读(Warings/Errors/Log)消息。
- HAProxy 会向stderr(标准错误输出) 输出配置错误信息;
- 当配置文件中出现错误的时候,warning消息会输出到stderr。
- 当开启日志记录的时候,可以发送消息到syslog
- HAProxy 会提供一条消息,来解释错误,有时候也会提供修复方法。 如下:
[WARNING] 177/011147 (8652) : Setting tune.ssl.default-dh-param to 1024 by default, if your workload permits it
Configuration file is valid
HAProxy 的日志信息非常丰富,也可以自定义日志格式,对于线上排查故障非常有用。
硬件推荐
由于HAProxy 的工作机制,需求如下:
- CPU:相对于多核心,更应该看重速度(也就是主频更高),和缓存大小。
- 需要足够的内存来处理TCP 连接,HAProxy 的开销以及系统的开销,千万不能忽视大量TCP连接带来的内存开销。
- 网卡:intel 是更好的选择。
- 硬盘:非必须,除非本地需要日志记录。
为了达到最佳性能,还需要一点调整:
- 把网卡中断和内核绑定在core 0 上;
- HAProxy 绑定在通一块物理CPU 的下一个核心上。
这个优化很有道理,也非常必要,特别是HAProxy 如果还是工作在单进程模式下,这样能最大化压榨性能。
注意:卸载irqbalance,irqbalance 是一个系统服务,可以在多个核心之间自动平衡中断。
延伸阅读:褚霸:《深度剖析告诉你irqbalance有用吗?》。
避免使用VM 或其他共享资源的云服务。
Sysctl 调优
最重要的调优:
- net.ipv4.ip_local_port_range = "1025 65534"
- net.ipv4.tcp_max_syn_backlog = 100000
- net.core.netdev_max_backlog = 100000
- net.core.somaxconn = 65534
- ipv4.tcp_rmem = "4096 16060 64060"
- ipv4.tcp_wmem = "4096 16384 262144"
调net.ipv4.ip_local_port_range,是因为HAProxy 需要充当中间人,开N多端口,连接前后端。调大了net.ipv4.tcp_max_syn_backlog,前者决定了三次握手之后,还没被HAProxy接收的TCP 连接的排队数量,超过了之后,系统不再接受新的请求,所以得调高这个值。net.core.somaxconn 是系统端口的监听队列,也得增大。ipv4.tcp_rmem和ipv4.tcp_wmem,减小默认值和最大值,防止内存爆了,关于TCP 内存这一块,可以看陶辉的这篇文章,写的很好:《高性能网络编程7--tcp连接的内存使用》。
如果有长连接,把tcp_slow_start_after_idle 设置为0,即关闭,防止长连接空闲之后,系统降低拥塞窗口,提升性能。
- tcp_slow_start_after_idle=0
关于iptables 的调优:
- net.netfilter.nf_conntrack_max = 131072
如果配置不合理,conntrack 会影响HAProxy 达到高性能。
注意:启用iptables,及使用连接跟踪(connection tracking ),会消耗20%的CPU 资源,即使没任何规则。
如果线上启用了iptables,特别还是在一些前端流量接入的机器上,例如Nginx,LVS,Haproxy之类,要好好优化一番iptables。
HAProxy的多进程模式
配置示例(摘自幻灯片):
# **DON'T RUN IN PRODUCTION, THERE ARE NO TIMEOUTS**
global
nbproc 2
cpu-map 1 1
cpu-map 2 2
stats socket /var/run/haproxy/socket_web process 1
stats socket /var/run/haproxy/socket_mysql process 2
defaults HTTP
bind-process 1
mode http
frontend f_web
bind 192.168.10.1:9000
default_backend b_web
backend b_web
server w1 192.168.10.21:8000 check
defaults MYSQL
bind-process 2
mode tcp
frontend f_mysql
bind 192.168.10.1:3306
default_backend b_mysql
backend b_mysql
server m1 192.168.10.11:3306 check
好处
一个进程处理一个任务,例如一个进程用于处理HTTP请求,一个用于MySQL,互相不干扰,见上文配置。
多进程可以绑定到多个核心上(cpu-map),扩展性也更好。另外如果HAProxy 需要进行SSL 卸载的话,多进程非常有用,可以更加充分的利用CPU 资源。
坏处
每个进程有自己的内存区域,带来的一些限制:
- 开启debug 模式时,多进程会退出,只启动单个进程;
- frontentd 和 对应的backend 必须运行在通一个进程上;
- 和Peers 冲突;(peers 是一个在haproxy 节点之间同步server 列表的功能,具体看haproxy 配置peers 一节)
- 存储在单个进程内存区域内的信息无法共享给其他进程
- stick table + tracked counters
- statistics(统计信息)
- server's maxconn (queue management)
- connection rate
- 每个HAProxy 进程自行进行监控检查:
- 每个service 需要被每个进程检查;
- 一个service 在不同进程中,某一刻的状态可能不同;
- 简单来说,就是后端的监控检查无法共享,导致资源浪费和状态不一致。
- 管理一个多进程的配置更加复杂。
Logging(日志)
Haproxy 的日志非常详细(虽然很简短),也非常重要,生产环境中如果条件允许,应该一致打开日志记录。另外日志格式可以自定义(log-format)。 另外也可以对不同的frontend 指定日志记录,将传输日志和事件日志分开,只记录error等等,具体见幻灯片。
Timeout(超时)
一些timeout解释:
- timeout client: 客户端不活跃的超时时间
- timeout connect: 和服务端建立TCP 连接的超时时间
- timeout server:
- TCP 模式:服务端不活跃的超时时间
- HTTP 模式:服务端处理响应内容的时间(返回504 状态码)
- timeout client-fin: 客户端处于FIN_WAIT 状态的最长时间
- timeout server-fin: 服务端处于FIN_WAIT 状态的最长时间
- HTTP 模式中最要的一些timeout:
- timouet http-request:客户端发送整个请求到服务端的用时(抵抗slowlowris-live 攻击)
- timeout http-keep-alive:http-keep-alive 时,保持连接,等待下个请求的超时时间
- timeout tunnel:tunnel 模式和websockets 下,连接不活跃的超时时间
- timeout queue:一个连接在队列中能待的最长时间
- timeout tarpit:how long the tarpitted connection is maintained(暂时不太理解这个状态)
一些超时配置示例,来源幻灯片:
HTTP 服务:
defaults HTTP
mode http
timeout http-request 10s
timeout client 20s
timeout connect 4s
timeout server 30s
timeout http-keep-alive 4s
# for websockets:
timeout tunnel 2m
timeout client-fin 1s
timeout server-fin 1s
TCP 长连接的服务,例如POP、IMAP 之类:
defaults HTTP
mode http
timeout client 1m
timeout connect 4s
timeout server 1m
timeout client-fin 1s
timeout server-fin 1s
Fetch
可以用来获取请求和响应的一些数据,也就是在haproxy 配置中可以使用一些变量,这些变量代表具体请求的一些内容,然后用它们来编写规则,更多细节参看幻灯片,以及官方这个文档:Fetching data samples。
ACL
可以有匿名或者命名的ACL 规则,使用acl 来给规则起名字:
acl api_path path_beg -i /api/
use_backend bk_api if api_path
匿名的规则,需要用大括号包起来:
use_backend bk_api if { path_beg -i /api/ }
多个ACL 规则可以共用一个名字,关系上为逻辑或,即匹配任何一条规则即可:
acl myapi path_beg -i /api/
acl myapi hdr_beg(Host) -i api.
use_backend bk_api if myapi
等价馀:
acl api_path path_beg -i /api/
acl api_vhost hdr_beg(Host) -i api.
use_backend bk_api if api_path || api_vhost
HTTP 规则
在HTTP 层,HAProxy 支持规则的定义,可以做下列事情:
- 允许或禁止某些请求或响应
- 转发流量
- 篡改header 或者URL
- 捕获请求内容
- 更新ACL 规则或map 内容等
在HTTP 规则中可以使用上文提到的fetch 变量,编写复杂的规则,例如:
http-request deny unless { req.hdr(Host) -i www.mydomain.com }
http-request redirect location /%[req.hdr(Host)]%[path] if { path_beg -i /api/ }
服务和应用保护
HAProxy 有请求队列,可以弊民后端服务被打挂,给server 配置合适的maxconn ,即可把后端服务收到的请求控制住。
HAProxy 团队有另外一份幻灯片,提供了更多HAProxy防DDoS的经验分享:《Presentation packetshield, solution de protection contre les DDoS réseau》。
另外可以对不同性能的后端,设置不同的maxconn,转发不同的请求,分流压力:
frontend f_myapp
use_backend b_light if { path_beg /api/ /foo/ /bar/ }
use_backend b_heavy if { path_beg /search /massivefoo /heavybar }
backend b_light
server s1 server1:80 maxconn 300
backend b_heavy
server s1 server1:80 maxconn 10
统计页面
HAProxy 内部会维护很多计数器,用做统计与展示。统计页面可以配置成一个web 页面,也可以是输出CSV格式的UNIX 的套接字(UNIX socket)。配置示例:
listen stats
bind-process 1
bind :9010
stats enable
stats uri /
stats auth demo:demo
stats realm Demo
stats admin if TRUE
如果开了多进程(nbproc > 1),我们上文提到的,HAProxy 进程直接的内存内容是不共享的,所以维护者各自的统计计数器,所以需要为每个进程创建一个状态页面或者UNIX socket。
最后提供一个用于Falcon Agent 的HAProxy监控采集脚本:30_haproxy_stats.sh。